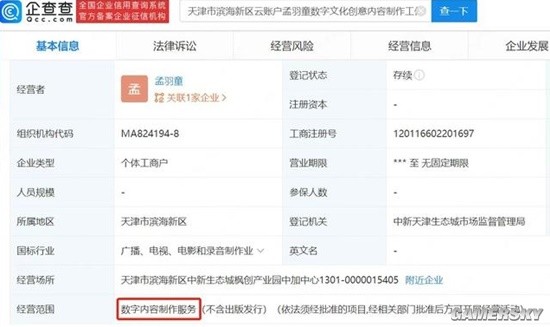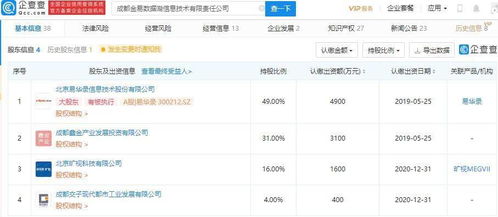
人工智能領域的領軍企業曠視科技完成對一家信息技術公司的戰略投資,引發業界廣泛關注。公開信息顯示,被投公司的經營范圍明確涵蓋了“數字內容制作服務”等關鍵領域。此舉不僅標志著曠視科技在核心的計算機視覺技術之外,正在積極探索業務邊界,也預示著數字內容產業與前沿AI技術融合的加速。
此次投資并非偶然。隨著元宇宙、數字孿生、虛擬現實等概念的興起,高質量、高效率的數字內容(包括3D模型、虛擬場景、互動媒體等)需求呈現爆發式增長。傳統的數字內容制作流程往往存在耗時耗力、成本高昂的瓶頸。而曠視科技所擅長的計算機視覺、深度學習、三維重建等技術,恰恰能在內容生成的自動化、智能化方面發揮巨大潛力。例如,通過AI快速生成或優化3D資產、實現真實場景的數字化高效復刻、驅動虛擬人物的自然交互等。投資一家擁有相關服務資質和經驗的公司,為曠視將這些技術能力進行場景化落地和商業化變現,提供了一個直接的切入點和業務支點。
從戰略層面看,這可以解讀為曠視科技在鞏固其智慧城市、智慧物流、智慧消費等既有To B優勢的向更廣闊的數字內容產業生態邁出的關鍵一步。數字內容服務是連接虛擬與現實、驅動未來數字經濟發展的基礎設施層之一。通過投資整合,曠視不僅能為其技術尋找新的應用出口,還能與被投公司形成技術互補與業務協同,共同打造從底層AI技術到上層內容應用的服務閉環,增強其在未來數字世界的綜合競爭力。
另一方面,對于被投資的這家信息技術公司而言,獲得曠視科技的投資意味著不僅僅是資本加持,更是獲得了頂尖的AI技術賦能。這能極大提升其在數字內容制作市場的技術壁壘和服務效率,從同質化競爭中脫穎而出,為客戶提供更具創新性和競爭力的解決方案。
曠視科技的這次投資動作,是AI巨頭賦能傳統產業、拓展生態疆域的典型案例。它反映了當前產業發展的一個清晰趨勢:人工智能正從“感知”與“識別”向“創造”與“生成”深入,數字內容產業將成為AI技術落地的重要戰場。這次“技術+內容”的聯姻,有望催生新的產品、服務與商業模式,為數字經濟的發展注入新的動能。后續雙方如何整合資源,推出具有顛覆性的數字內容生產解決方案,值得持續關注。